4. Working with Key/Value Pairs
Pair RDDs are a useful building block in many programs, as they expose operations that allow you to act on each key in parallel or regroup data across the network.
Creating Pair RDDs
pairs = lines.map(lambda x: (x.split(" ")[0], x))
Transformations on Pair RDDs
![]()
![]()
flatMapValues() checkout this
combineByKey(), Per-key average using combineByKey() in Python
sumCount = nums.combineByKey(
(lambda value: (value,1)),
(lambda x, value: (x[0] + value, x[1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1])))
sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()
reference from this
Create a Combiner
lambda value: (value, 1)
The first required argument in the combineByKey method is a function to be used as the very first aggregation step for each key. The argument of this function corresponds to the value in a key-value pair. If we want to compute the sum and count using combineByKey, then we can create this “combiner” to be a tuple in the form of (sum, count). The very first step in this aggregation is then (value, 1), where value is the first RDD value that combineByKey comes across and 1 initializes the count.
Merge a Value
lambda x, value: (x[0] + value, x[1] + 1)
The next required function tells combineByKey what to do when a combiner is given a new value. The arguments to this function are a combiner and a new value. The structure of the combiner is defined above as a tuple in the form of (sum, count) so we merge the new value by adding it to the first element of the tuple while incrementing 1 to the second element of the tuple.
Merge two Combiners
lambda x, y: (x[0] + y[0], x[1] + y[1])
The final required function tells combineByKey how to merge two combiners. In this example with tuples as combiners in the form of (sum, count), all we need to do is add the first and last elements together.
Tuning the level of parallelism
Every RDD has a fixed number of partitions that determine the degree of parallelism to use when executing operations on the RDD.
Most of the operators discussed in this chapter accept a second parameter giving the number of partitions to use when creating the grouped or aggregated RDD.
Grouping Data
With keyed data a common use case is grouping our data by key—for example, view‐ ing all of a customer’s orders together.
Joins
rdd_1.join(rdd_2)
rdd_1.leftOuterJoin(rdd_2)
rdd_1.rightOuterJoin(rdd_2)
Sorting Data
Sorting integers as if strings
rdd.sortByKey(ascending=True, numPartitions=None, keyfunc = lambda x: str(x))
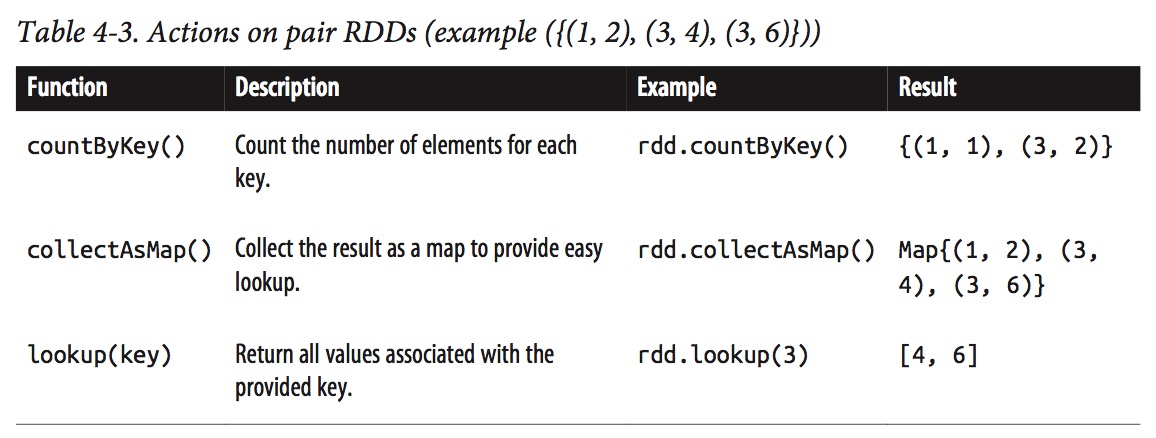
Actions Available on Pair RDDs
Data Partitioning (Advanced)
Spark’s partitioning is available on all RDDs of key/value pairs, and causes the system to group elements based on a function of each key.
Join without partitionBy()

Join with partitionBy()

val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...")
.partitionBy(new HashPartitioner(100)) // Create 100 partitions
.persist()
Spark’s Java and Python APIs benefit from partitioning in the same way as the Scala API. However, in Python, you cannot pass a Hash Partitioner object to partitionBy; instead, you just pass the number of partitions desired (e.g., rdd.partitionBy(100)).
Many of Spark’s operations involve shuffling data by key across the network. All of these will benefit from partitioning. As of Spark 1.0, the operations that benefit from partitioning are cogroup(), groupWith(), join(), leftOuterJoin(), rightOuter Join(), groupByKey(), reduceByKey(), combineByKey(), and lookup().
PageRank
checkout this article
// Assume that our neighbor list was saved as a Spark objectFile
val links = sc.objectFile[(String, Seq[String])]("links")
.partitionBy(new HashPartitioner(100))
.persist()
// Initialize each page's rank to 1.0; since we use mapValues, the resulting RDD
// will have the same partitioner as links
var ranks = links.mapValues(v => 1.0)
// Run 10 iterations of PageRank
for(i<-0until10){
val contributions = links.join(ranks).flatMap {
case (pageId, (links, rank)) =>
links.map(dest => (dest, rank / links.size))
}
ranks = contributions.reduceByKey((x, y) => x + y).mapValues(v => 0.15 + 0.85*v)
}
// Write out the final ranks
ranks.saveAsTextFile("ranks")
Although the code itself is simple, the example does several things to ensure that the RDDs are partitioned in an efficient way, and to minimize communication:
- Notice that the links RDD is joined against ranks on each iteration. Since links is a static dataset, we partition it at the start with partitionBy(), so that it does not need to be shuffled across the network. In practice, the links RDD is also likely to be much larger in terms of bytes than ranks, since it contains a list of neighbors for each page ID instead of just a Double, so this optimization saves considerable network traffic over a simple implementation of PageRank (e.g., in plain MapReduce).
- For the same reason, we call persist() on links to keep it in RAM across iterations.
- When we first create ranks, we use mapValues() instead of map() to preserve the partitioning of the parent RDD (links), so that our first join against it is cheap.
- In the loop body, we follow our reduceByKey() with mapValues(); because the result of reduceByKey() is already hash-partitioned, this will make it more effi‐ cient to join the mapped result against links on the next iteration.