3. Programming with RDDs
In Spark all work is expressed as either creating new RDDs, transforming existing RDDs, or calling operations on RDDs to compute a result.
RDD Basics
An RDD in Spark is simply an immutable distributed collection of objects. Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster.
Although you can define new RDDs any time, Spark computes them only in a lazy fashion—that is, the first time they are used in an action.
Finally, Spark’s RDDs are by default recomputed each time you run an action on them. If you would like to reuse an RDD in multiple actions, you can ask Spark to persist it using RDD.persist(). In practice, you will often use persist() to load a subset of your data into memory and query it repeatedly.
lines = sc.textFile("README.md")
pythonLines = lines.filter(lambda line: "Python" in line)
pythonLines.persist
pythonLines.count()
pythonLines.first()
Creating RDDs
SparkContext’s parallelize() is very useful when you are learning Spark, since you can quickly create your own RDDs in the shell and perform operations on them. Keep in mind, however, that outside of prototyping and testing, this is not widely used since it requires that you have your entire dataset in memory on one machine. A more common way to create RDDs is to load data from external storage, which is SparkContext.textFile().
RDD Operations
Transformations are operations on RDDs that return a new RDD, such as map() and filter(). Actions are operations that return a result to the driver program or write it to storage, and kick off a computation, such as count() and first().
If you are ever confused whether a given function is a transformation or an action, you can look at its return type: transformations return RDDs, whereas actions return some other data type.
Transformations, Note that the filter() operation does not mutate the existing inputRDD. Instead, it returns a pointer to an entirely new RDD. So, there will generate three RDDs in memory from below code. A better way would be to simply filter the inputRDD once, looking for either error or warning.
errorsRDD = inputRDD.filter(lambda x: "error" in x)
warningsRDD = inputRDD.filter(lambda x: "warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
Actions, take(), which collects a number of elements from the RDD. RDDs also have a collect() function to retrieve the entire RDD, keep in mind that your entire dataset must fit in memory on a single machine to use collect() on it, so collect() shouldn’t be used on large datasets.
print "Input had " + badLinesRDD.count() + " concerning lines"
print "Here are 10 examples:"
for line in badLinesRDD.take(10):
print line
Lazy Evaluation
Rather than thinking of an RDD as containing specific data, it is best to think of each RDD as consisting of instructions on how to compute the data that we build up through transformations.
In Spark, there is no substantial benefit to writing a single complex map instead of chaining together many simple operations.
Passing Functions to Spark
One issue to watch out for when passing functions is inadvertently serializing the object containing the function.
class WordFunctions(object):
def getMatchesNoReference(self, rdd):
# Safe: extract only the field we need into a local variable
query = self.query
return rdd.filter(lambda x: query in x)
def getMatchesMemberReference(self, rdd):
# Problem: references all of "self" in "self.query"
return rdd.filter(lambda x: self.query in x)
Common Transformations
![]()
![]()
Common Actions
Similar to reduce() is fold(), which also takes a function with the same signature as needed for reduce(), but in addition takes a “zero value” to be used for the initial call on each partition. The zero value you provide should be the identity element for your operation; that is, applying it multiple times with your function should not change the value (e.g., 0 for +, 1 for *, or an empty list for concatenation).


Persistence (Caching)
val result = input.map(x => x * x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))
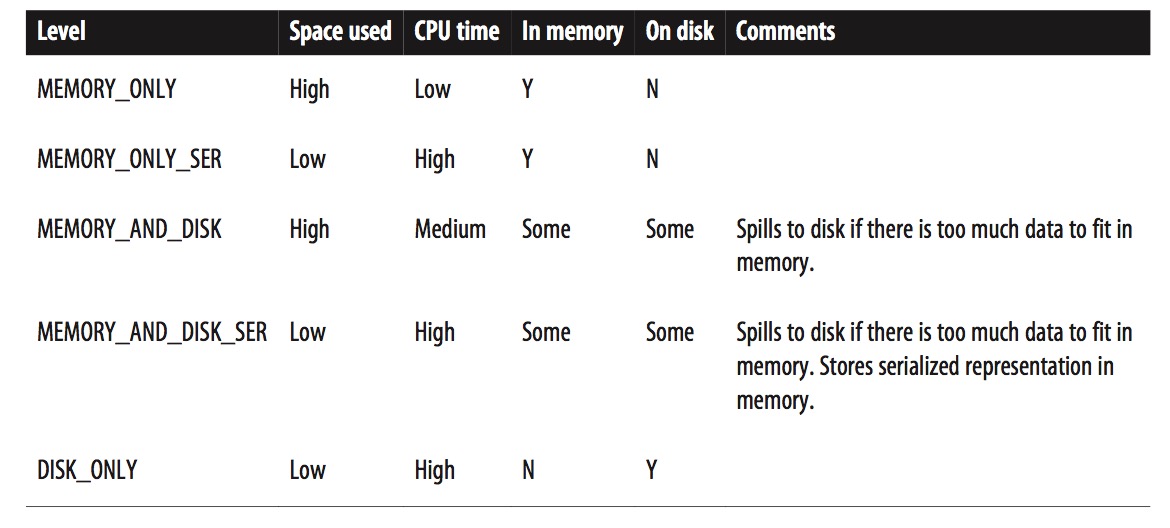 If you attempt to cache too much data to fit in memory, Spark will automatically evict old partitions using a Least Recently Used (LRU) cache policy. For the memory only storage levels, it will recompute these partitions the next time they are accessed, while for the memory-and-disk ones, it will write them out to disk. In either case, this means that you don’t have to worry about your job breaking if you ask Spark to cache too much data. However, caching unnecessary data can lead to eviction of useful data and more recomputation time.
Finally, RDDs come with a method called unpersist() that lets you manually remove them from the cache.
If you attempt to cache too much data to fit in memory, Spark will automatically evict old partitions using a Least Recently Used (LRU) cache policy. For the memory only storage levels, it will recompute these partitions the next time they are accessed, while for the memory-and-disk ones, it will write them out to disk. In either case, this means that you don’t have to worry about your job breaking if you ask Spark to cache too much data. However, caching unnecessary data can lead to eviction of useful data and more recomputation time.
Finally, RDDs come with a method called unpersist() that lets you manually remove them from the cache.